In practice, most system failures are not caused by a single application going down.
They happen in the seams between systems.
A directory service is available, but delayed. An API responds, but with incomplete data. A downstream platform accepts a request, but processes it differently than expected. A queue retries an operation that was never designed to be idempotent. A user’s identity state changes in one place but not another. Individually, each issue seems manageable. Together, they create the kinds of failures that are hardest to predict, hardest to diagnose, and most disruptive to the people relying on the system.
That is the reality of cross-system architecture.
In many organizations, the most important technical work is no longer happening inside a single application boundary. It happens across identity systems, authentication services, APIs, internal applications, vendor platforms, source-of-truth systems, and infrastructure layers that all have to behave like a coherent whole, even though they were never really designed together.
That complexity is where architecture becomes real.
Over time, one lesson becomes obvious: the hardest part of system design is not building a system that works on its own. It is building a collection of systems that continue to work together as scale, complexity, and organizational dependencies increase.
The Real Problem Is Almost Never “The System”
When engineers talk about reliability, it is common to focus on the health of individual components.
Is the API up?
Is the database healthy?
Is the authentication service responding?
Is the queue draining?
Those are important questions, but they often miss the real failure domain.
However, a system can be technically “up” and still create failure conditions for everything around it.
An API may return stale data.
An authentication service may validate users correctly but fail on a subset of integrations.
A downstream system may accept requests but process them with side effects that were never anticipated.
A source-of-truth system may change state in ways that ripple across dependent systems with no coordinated handling.
In cross-system environments, reliability is not just about uptime. It is about the consistency of behavior across boundaries.
That is much harder.
Integration Creates Hidden Complexity
At first, most integration work looks straightforward.
System A sends data to System B.
System B updates System C.
System C triggers access changes in System D.
On a diagram, this seems manageable.
In production, every connection introduces its own set of assumptions:
- Assumptions about timing
- Assumptions about field formats
- Assumptions about ownership
- Assumptions about retries
- Assumptions about what “success” even means
More importantly, these assumptions are often implicit. They live in code, tribal knowledge, half-remembered implementation details, and operational habits rather than in formal architectural boundaries.
That is when systems start to drift from design into fragility.
The deeper the integration footprint becomes, the more important it is to move from “connecting systems” to governing interactions.
That means designing:
- Explicit contracts
- Known ownership boundaries
- Predictable state transitions
- Consistent error handling
- Observable execution paths
Without those, integration becomes accumulation rather than architecture.
Data Models Break More Often Than APIs
At the same time, engineers often focus on protocol and transport: REST, SOAP, queues, events, authentication methods, and retry patterns.
But in many real-world environments, the deeper source of failure is not the transport layer. It is the semantic mismatch between data models.
Different systems do not think about identity, roles, status, ownership, or lifecycle in the same way.
One system may treat a user as active because they exist in a directory.
Another may treat them as active because HR says they are employed.
Another may treat them as active because they still have application access.
Yet another may have no real concept of lifecycle at all.
If those models are not normalized somewhere, the architecture becomes a negotiation between conflicting definitions of reality.
That is where many subtle failures come from:
- Duplicate identities
- Stale affiliations
- Access lingering after role changes
- Inconsistent permissions across systems
- Operational confusion over which system is actually authoritative
Strong cross-system design requires more than integration logic. It requires data model discipline. This becomes even more important in environments governed by formal digital identity standards.
The architecture has to answer:
- What is the source of truth for this field?
- Which system owns this state?
- What events can change it?
- Which transitions are valid?
- What happens if systems disagree?
If those answers are not clear, the failure is already in the design.
Idempotency Is Not Optional
For example, one of the most common reliability problems in distributed or cross-system workflows is retry behavior without idempotent design.
This shows up everywhere:
- Provisioning
- Deprovisioning
- Group synchronization
- Messaging
- Role assignment
- Downstream updates triggered by lifecycle changes
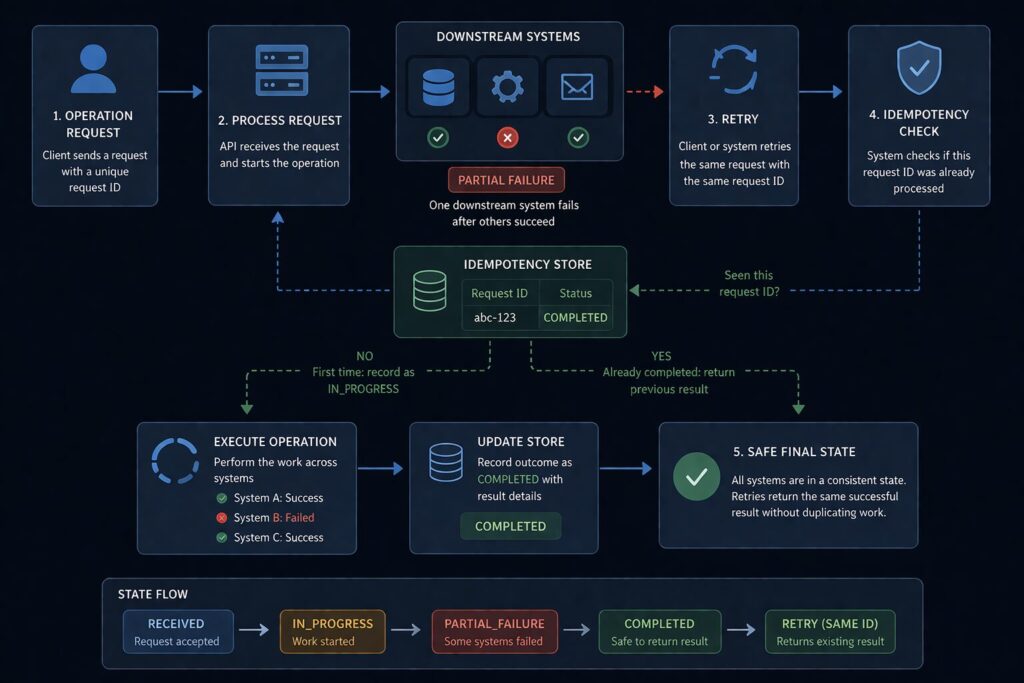
The problem is simple: retries are necessary, but retries without idempotency create duplication, conflicting state, or unintended side effects.
A transient failure occurs.
The operation retries.
The downstream system partially processed the original request.
Now the system has two attempts, one partial outcome, and an ambiguous state.
That ambiguity is expensive.
It is expensive technically because it creates cleanup work, reconciliation logic, and harder debugging.
It is operationally expensive because it creates mistrust in the automation.
It is organizationally expensive because people begin working around the system.
If a workflow may be retried—and in real systems, it almost always may—then it must be designed to tolerate repeated execution safely.
That means:
- Stable identifiers
- Repeatable operations
- Explicit state checks
- Clear success/failure semantics
- Bounded side effects
Without idempotency, reliability is always fragile.
Asynchrony Helps — If It Is Designed, Not Assumed
As systems grow, asynchronous processing becomes increasingly attractive.
Queues, event-based workflows, delayed retries, and decoupled processors can improve resilience and scalability. They also reduce the need for tightly synchronized dependencies.
However, asynchrony is not a magic solution. It simply changes the failure mode.
Instead of an obvious synchronous failure, you get:
- Delayed failure
- Reordered events
- Duplicate processing
- Eventual consistency issues
- Harder observability
- More complex reconciliation
In other words, you trade coupling for coordination complexity.
That trade is often worth making, but only if the architecture accounts for it intentionally.
A sound asynchronous design requires:
- Clear event meaning
- Replay-safe consumers
- Durable message handling
- Visibility into queue health and processing lag
- Explicit ownership of compensation and reconciliation
When done well, asynchronous design creates resilience.
When done poorly, it creates a system that appears healthy while silently accumulating inconsistency.
Observability Must Cross Boundaries
In reality, many teams think they have observability because each system has logs.
That is not the same as observability across a workflow.
In cross-system environments, the hardest problems are usually not “what happened inside one system?” They are:
- Where did the workflow begin?
- What did it call?
- Which system transformed the data?
- Where did the state diverge?
- Which dependency introduced the delay?
- Where did the final outcome stop matching the intended transition?
Without end-to-end visibility, incident response becomes manual reconstruction.
That is slow, error-prone, and exhausting.
Meaningful cross-system observability requires:
- Correlation IDs or workflow identifiers
- Consistent logging conventions
- Explicit state transition logging
- Metrics that reflect end-to-end outcomes, not only per-system health
- Traceability across integration boundaries
The point is not just debugging faster. It is making distributed complexity understandable enough that you can improve it.
If engineers cannot see the system as a whole, they cannot reliably operate it as a whole.
Reliability Needs Validation Against Reality
Similarly, one of the easiest traps in systems engineering is relying too heavily on synthetic validation.
Unit tests pass.
Integration mocks pass.
Health checks are green.
A deployment succeeds.
And yet the real system still breaks.
Why?
Because the behavior that matters most often lives in the interaction between real systems under real conditions.
Authentication is a perfect example. A change may work against a test harness and still fail when exercised through actual upstream or downstream integrations. Timing, redirects, claims, data assumptions, or side effects may all behave differently when the full chain is involved.
This is why testing against real integrations—safely, intentionally, and before production exposure—can be one of the highest-value reliability investments a team can make.
Not every workflow can be fully validated this way, but the principle matters:
The closer validation gets to real behavior, the more trustworthy it becomes.
Mocked confidence is not the same as operational confidence.
Ownership Is an Architectural Requirement
Just as importantly, Cross-system architecture fails quickly when ownership is vague.
This is one of the least glamorous and most important truths in engineering.
If no one can clearly answer:
- Who owns this workflow?
- Who owns this data?
- Who defines valid transitions?
- Who is responsible when the state diverges?
Then the architecture is already unstable.
Shared responsibility sounds collaborative, but in many environments, it becomes operational ambiguity.
Good architecture does not eliminate collaboration. It creates enough ownership clarity that collaboration can actually function.
That means defining:
- System authority
- Data stewardship
- Escalation paths
- Change boundaries
- Approval or coordination expectations where necessary
Ownership is not bureaucracy. It is what keeps cross-system design from collapsing into negotiation during incidents.
Simplicity Is a Reliability Strategy
As complexity grows, there is a strong temptation to respond with more abstraction, more flexibility, more rules, more layers, and more dynamic behavior.
Sometimes that is necessary.
Often, it is not.
The most resilient systems I have seen tend to share a few qualities:
- They are explicit
- They are predictable
- They hide less magic
- They define boundaries clearly
- They are easier to reason about under failure conditions
This is especially important in cross-system environments, where complexity compounds.
One complicated system is difficult.
Five systems with hidden complexity in their interactions become a long-term reliability problem.
Simplicity is not about being basic. It is about reducing the number of ways the system can surprise you.
At scale, that matters more than elegance.
Architecture Has to Survive Organizational Reality
One of the most overlooked aspects of cross-system design is that systems evolve inside organizations, not diagrams.
Over time, teams change, priorities shift, and vendors update their behavior.
Ownership moves. New systems get added before old ones are retired. Operational shortcuts become permanent.
A design that only works under ideal governance will not hold up for long.
Strong architecture has to survive:
- Imperfect documentation
- Partial ownership transitions
- Legacy dependencies
- Evolving business requirements
- Changing operational maturity
That means building systems that are not only technically sound, but also understandable and supportable by the organization that has to live with them.
This is one reason the best designs often look more conservative than the most clever ones.
Clever designs impress engineers.
Durable designs survive change.
Final Thought
These same reliability and ownership challenges show up constantly in platform engineering work, where teams are responsible not just for systems, but for the paths between them.”
Cross-system architectures do not fail because integration is hard in the abstract.
They fail because real environments expose every unclear assumption:
- Who owns state
- What success means
- How retries behave
- Where authority lives
- How workflows are observed
- What happens when dependencies are only partially healthy
The more critical the system, the more those questions matter.
Ultimately, the goal is not to connect everything
It is to create a system of interactions that remains understandable, reliable, and governable as complexity grows.
That is the difference between having integrations and having architecture.